
자바(Java) - 컬렉션 프레임워크
컬렉션 프레임워크(Collection Framework)
-
여러 데이터를 편리하게 관리할 수 있게 만들어 놓은 것
-
즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것

리스트(List)
- 순서가 있는 데이터의 집합으로, 데이터의 중복을 허용
- 대표적인 구현 클래스: Vector, ArrayList, LinkedList
1
2
3
Vector v = new Vector();
ArrayList list1 = new ArrayList();
LinkedList list2 = new LinkedList();
1. Array List
- ArrayList 클래스는 가장 많이 사용되는 컬렉션 클래스 중 하나
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
ArrayList list1 = new ArrayList();
// add() 메소드를 이용한 요소의 저장
list1.add(1);
list1.add(3);
list1.add(2);
list1.add(8);
list1.add(5);
// for 문과 get() 메소드를 이용한 요소의 출력
for (int i = 0; i < list1.size(); i++) {
System.out.print(list1.get(i) + " ");
}
// remove() 메소드를 이용한 요소의 제거
list1.remove(1); //1번 인덱스의 값을 제거
list1.remove(Integer.valueOf(1)); //값이 1인 요소 제거
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (Object e : list1) {
System.out.print(e + " ");
}
// Collections.sort() 메소드를 이용한 요소의 정렬
Collections.sort(list1);
// size() 메소드를 이용한 요소의 총 개수
System.out.println("리스트의 크기 : " + list1.size());
2. Linked List
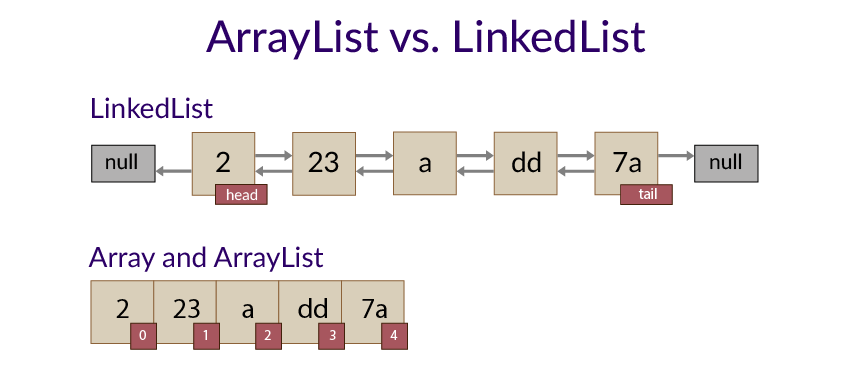
-
위 그림과 같이 ArrayList는 값을 찾을 때 순차적으로 찾는 구조이다.
-
하지만 데이터 전체를 순환해야하는 단점이 있기 때문에 이러한 단점을 보완하기 위해서 나온 LinkedList는 역순으로도 자료 검색이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
LinkedList list2 = new LinkedList();
// add() 메소드를 이용한 요소의 저장
list2.add(4);
list2.add(1);
list2.addFirst(2); //첫번째 인덱스에 값을 저장
list2.addLast(3); //마지막 인덱스에 값을 저장
// for 문과 get() 메소드를 이용한 요소의 출력
for (int i = 0; i < list2.size(); i++) {
System.out.print(list2.get(i) + " ");
}
// remove() 메소드를 이용한 요소의 제거
list2.remove(1);
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (Object e : list2) {
System.out.print(e + " ");
}
// size() 메소드를 이용한 요소의 총 개수
System.out.println("리스트의 크기 : " + list2.size());
셋(Set)
- 순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않음
- 대표적인 구현 클래스: HashSet, TreeSet
1
2
HashSet set1 = new HashSet();
TreeSet set2 = new TreeSet();
1.HashSet
- HashSet 클래스는 Set 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
HashSet set1 = new HashSet();
// add() 메소드를 이용한 요소의 저장
set1.add(1);
set1.add(2);
set1.add(3);
set1.add(3); //중복된 값은 저장되지 않는다.
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (Object e : set1) {
System.out.print(e + " ");
}
// remove() 메소드를 이용한 요소의 제거
set1.remove(2); //index값이 아닌 요소의 값으로 지운다.(set은 순서가 없는 데이터 집합)
// size() 메소드를 이용한 요소의 총 개수
System.out.println("집합의 크기 : " + set1.size());
2. TreeSet
-
TreeSet 클래스는 데이터가 정렬된 상태로 저장되는 이진 검색 트리(binary search tree)의 형태로 요소를 저장
-
이진 검색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
TreeSet set2 = new TreeSet();
// add() 메소드를 이용한 요소의 저장
set2.add(2);
set2.add(10);
set2.add(20);
set2.add(30);
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
for (Object e : set2) {
System.out.print(e + " ");
}
// remove() 메소드를 이용한 요소의 제거
set2.remove(2);
// size() 메소드를 이용한 요소의 총 개수
System.out.println("이진 검색 트리의 크기 : " + set2.size());
// TreeSet을 이용한 출력
System.out.println(set2.first()); //가장 작은 값 출력(알파벳 : 대문자A ~ 소문자z 순서)
System.out.println(set2.last()); //가장 높은 값 출력
System.out.println(set2.lower(20)); //20보다 낮은 값 출력
System.out.println(set2.higher(20)); //20보다 높은 값 출력
맵(Map)
-
키와 값의 한 쌍으로 이루어지는 데이터의 집합으로 순서가 없다.
-
이때 키는 중복을 허용하지 않지만, 값은 중복될 수 있습니다.
- 대표적인 구현 클래스는 HashMap, TreeMap이 있습니다.
1
2
HashMap map1 = new HashMap();
TreeMap map2 = new TreeMap();
1. HashMap
- HashMap 클래스는 Map 컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
HashMap map1 = new HashMap();
// put() 메소드를 이용한 요소의 저장
map1.put(1, "apple");
map1.put(2, "banana");
map1.put(3, "mango");
map1.put(4, "kiwi");
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
System.out.println("맵에 저장된 키들의 집합 : " + map1.keySet());
for (Object key : map1.keySet()) {
System.out.println(String.format("키 : %s, 값 : %s", key, map1.get(key)));
}
// remove() 메소드를 이용한 요소의 제거
map1.remove(2);
// size() 메소드를 이용한 요소의 총 개수
System.out.println("맵의 크기 : " + map1.size());
2. TreeMap
-
TreeMap 클래스는 키와 값을 한 쌍으로 하는 데이터를 이진 검색 트리(binary search tree)의 형태로 저장
-
이진 검색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
TreeMap map2 = new TreeMap();
// put() 메소드를 이용한 요소의 저장
map2.put(10, "apple");
map2.put(5, "banana");
map2.put(15, "mango");
map2.put(20, "kiwi");
// Enhanced for 문과 get() 메소드를 이용한 요소의 출력
System.out.println("맵에 저장된 키들의 집합 : " + map2.keySet());
for (Object key : map2.keySet()) {
System.out.println(String.format("키 : %s, 값 : %s", key, map2.get(key)));
}
// remove() 메소드를 이용한 요소의 제거
map2.remove(20);
// size() 메소드를 이용한 요소의 총 개수
System.out.println("맵의 크기 : " + map2.size());
// TreeMap을 이용한 출력
System.out.println(map2.firstKey());
System.out.println(map2.firstEntry());
System.out.println(map2.lastKey());
System.out.println(map2.lastEntry());
System.out.println(map2.lowerEntry(10));
System.out.println(map2.higherEntry(10));
댓글남기기